In preparation for the PDF Liberation Hackathon, we’re putting together a short how-to of different PDF Liberation tools starting with Tabula – a tool to extract tables of data from PDFs.
Tabula
Tabula is an open source tool built by Manuel Aristarán with the help of ProPublica, La Nación DATA and Knight-Mozilla OpenNews.
When you first open Tabula, you’re given the option to load PDFs into the system. For this example, we’ve taken the monthly veterans report from the Illinois Department of Employment Security (currently only available in PDF) and loaded it into Tabula.

Once you upload it, Tabula will process the file. This can take a little bit of time depending on the size of the file.
Once it’s loaded, you simply draw rectangulars over the tables in the PDF.
From there, Tabula will show you the data that’s it’s captured. Now, you can copy the data to the clipboard or download to your own local machine as a file. It’s that simple.
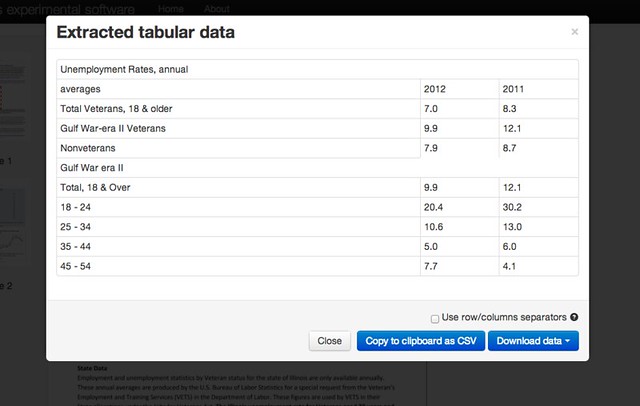
You can find more information on how Tablua works on Source. You can also find a list of other PDF extraction tools on the national PDF Liberation Hackathon homepage.
OpenRefine
Once you get the data into a csv, you may have to clean up the data. A common tool to do this is OpenRefine (formally Google Refine). You can load a CSV file into OpenRefine and dig into the data to find possible data entry errors (somebody writing in Chicgo instead of Chicago), transform the data (change the format of a cell to show currency instead of text), and easily spot inconsistencies in the data (One set of entries classified as ‘phone’ and another ‘phone number’.
OpenRefine also has comprehensive documentation on how to use it including videos tutorials. Here’s the video that introduces OpenRefine.
You can find out more information on OpenRefine on their website.
Google Fusion Tables
Once you have the data you’re interested in, you can load it into Google Fusion Tables in order to build apps that use the data.
Google Fusion Tables operates much the same way an Excel spreadsheet does. The difference is that you can use the Google Fusion Table API to load data into your civic app. A good example of this is Derek Eder’s Searchable Map Template.
Do you have PDFs that need liberated? Interested in freeing the data?
If you have PDF’s that you’d like to see data extracted from, you can fill out wufoo form here. If you’re interested in taking part in the PDF Liberation hackathon, you can RSVP for the event here.
 Website")




