Note: this is a guest post from Jonathan Giuffrida. Jonathan has been working at 1871 in one of the seats we maintain there for innovators in civic technology. Here’s more on that program.

Jonathan Giuffrida
This summer, I’ve been using Smart Chicago’s space in 1871 to help work on a new product that is intended to change the way we use open data.
Plenar.io was conceived as a centralized hub for open datasets from around the country. Funded by the NSF and the MacArthur Foundation, and led by a team of prominent open data scientists, researchers, and developers, it is a collaborative, open-source solution to the problems inherent to the rapid growth in government data portals.
The primary innovations of Plenario focus on making data easier for anybody to find, access, and download, regardless of its original source or format, and to do so in a free and efficient manner. The result is an enormous improvement to the ecosystem that returns us to the core promise of making the data open in the first place – that it can help improve our cities, our governments, and our lives.
The landscape
First, let’s take a step back and talk about how we currently use open data. Governments from the city level to the federal level are putting more and more data online about how they operate and what occurs in their jurisdictions, and they are joined by organizations and companies more and more willing to share the data they collect. This powers a rapidly growing community of developers and apps, many of which have been covered on this blog.
But the system could work much better. Say you’re a researcher or developer interested in an area in space, rather than any particular dataset. For a location in the Loop, you would need to search the data portals for the City of Chicago, Cook County, the state of Illinois, and the federal government, and it would be difficult to tell what datasets include the specific area and time period you’re interested in without searching every one of them. That may not even include crucial datasets such as NOAA weather or the Census, or other data portals run by organizations rather than governments.
Furthermore, you might want to look at complicated questions that require multiple datasets. Sometimes these datasets are on the same portal, but sometimes they are not—such as when comparing energy usage in the Loop (housed on Chicago’s portal) to weather (housed at the federal NOAA website). That could require even more work to unify the data into a format useful for research or app development.
How can we go beyond individual databases to see the big picture? (City of Chicago / National Oceanic and Atmospheric Administration data portals)
See the common thread here? There is an enormous amount of open data available, but the siloed nature of data portals adds an extra burden for each additional dataset you want to use—and makes it very difficult to even see what is relevant for a given location. Furthermore, each dataset may have its own way of recording spatial and temporal information, requiring more work to piece together how points are related to each other—such as locating the closest weather station to each block in the Loop.
All of this frequently involves hiring an RA or junior developer to write the code and work out the kinks, which may be why it’s uncommon to see a tool or journal article using data from multiple significantly different datasets, despite the wide availability of the data itself. And the complexity rises with more datasets. Theoretically, for your energy usage research, you might want to perform a more statistically rigorous analysis by including every city that releases energy usage data (because we know Chicago weather is a little out of the ordinary). But the added benefit is rarely worth the additional workload.
The Plenario solution
Enter the Plenario platform, which has two core innovations to address these problems. The first is to house all open datasets in one location, which allows them all to be accessed via the same API. This is driven by an automated system to import datasets of multiple formats, whether originally housed by open data portals or on a researcher’s hard drive, and make them easy for everyone to access. The second is to link all datasets via a single temporal and spatial index, so that Plenario automatically knows how close two data points from different datasets are in space and time. Everything is extremely accessible even without technical knowledge.
Put these together, and accessing the Loop’s energy usage and weather during summer 2014 can be done in a single query. In fact, you can even link the datasets by asking Plenario for the weather conditions at every point where we measure energy usage, rather than performing the computations yourself. The data can be viewed as a time series (a count of the number of observations) or in its original format, and downloaded in one click.
Furthermore—and we think this is perhaps the most important innovation—Plenario simplifies the API to the point that you can use it by drawing on a map:
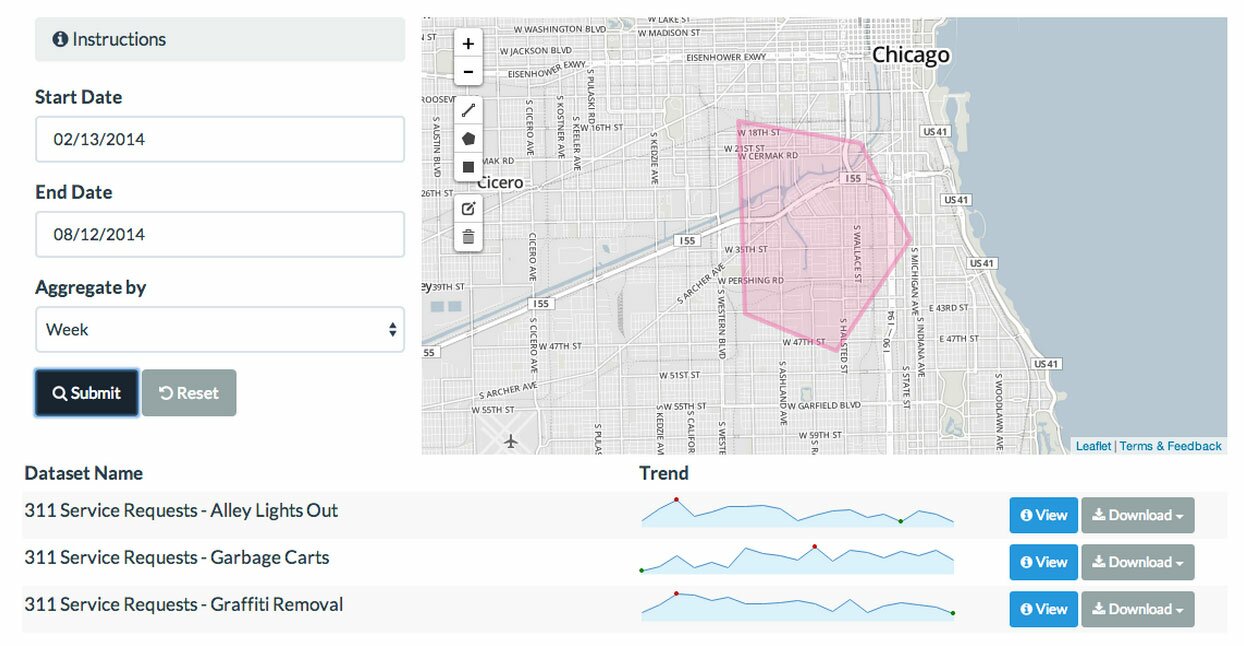
Map interface for easy API use
That means you no longer need to know how to code to collect the data you’re interested in. The data is “open”, after all—and we think “open” should mean that everyone can use it regardless of technical background.
A better world
These innovations also allow a user to ask important questions that might have been neglected when working with traditional open data portals. For instance: how does a region change over time, along multiple variables? Here is a snapshot of downtown Chicago during 2013:
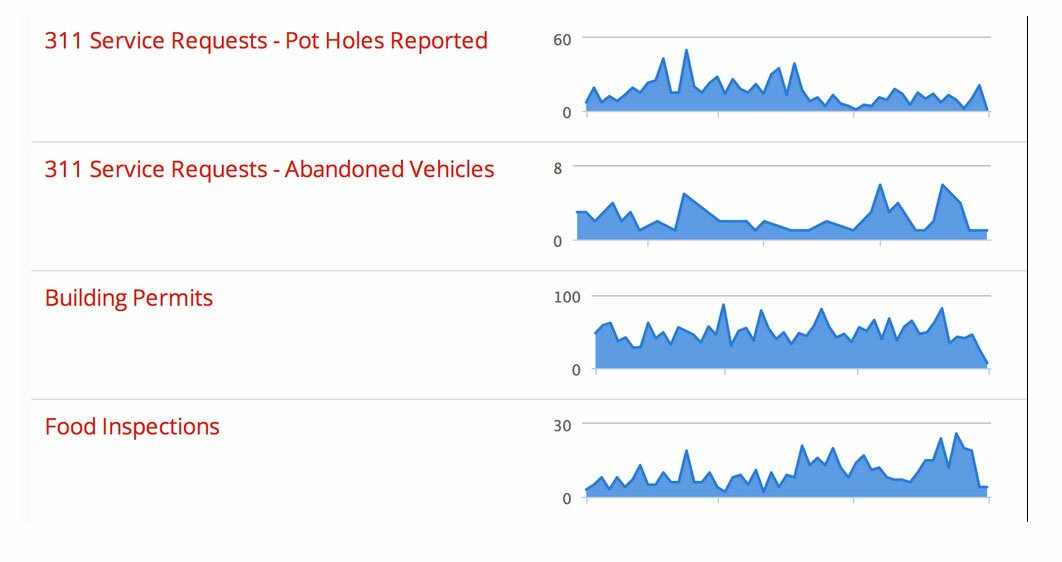
Downtown Chicago, 2013
What data exists for south-side Chicago in 2005?
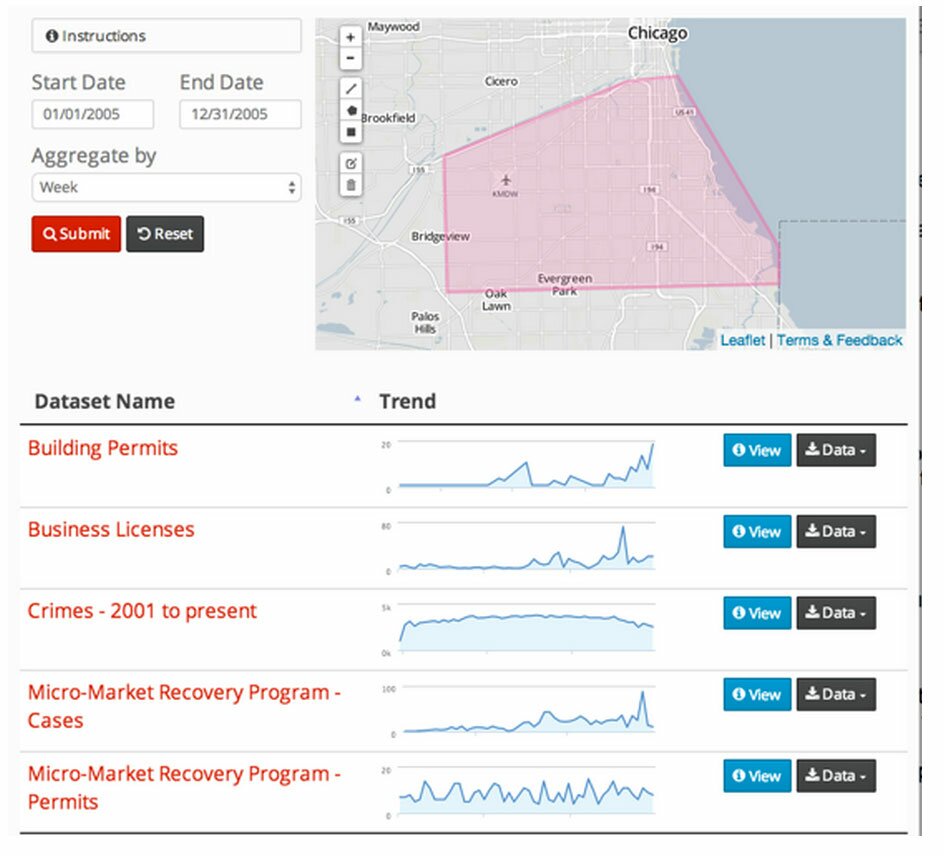
Southside Chicago, 2005
(Note: Plenario houses data from around the country, not only Chicago. That’s just our bias.)
More importantly, Plenario provides governments—especially small, municipal governments—with greater incentives to release their data so that it can be incorporated into Plenario and thus allow those same city workers to create and use a host of data-driven tools to analyze and improve city services.
Open-source and free to use
Crucially, Plenario is completely open-source and free to use, because it aims to be the platform for a new generation of open data products. It will be up to researchers and developers—including many of Smart Chicago’s partners—to ask the right questions and create products to answer them. It is also fully extensible and can be forked via GitHub or through Amazon Web Services to provide the back-end for custom applications.
The platform is still in its early stages, but has ambitious goals for its future. It’s funded by a grant from the NSF under its EAGER program (Early-concept Grants for Exploratory Research), and by the MacArthur foundation, both of which are excited to see where it goes. The project is being led by Brett Goldstein, Chicago’s former Chief Data Officer and CIO (who is now the inaugural Senior Fellow for Urban Science at the Harris School), and Charlie Catlett, Senior Computer Scientist at Argonne and a Senior Fellow at the Computation Institute. Key product decisions and ongoing vision have been contributed by Dan X. O’Neil here at Smart Chicago. UrbanCCD at the University of Chicago is implementing Plenario along with DataMade, which has extensive experience designing apps to work with open data.
The alpha version of Plenario will be officially launched by Goldstein during his plenary speech at the Code for America summit on September 23. It is our hope that by reducing barriers to comprehensive research and by improving accessibility to open datasets, Plenario can help spark a new phase in urban science, government accountability, and data-oriented policy making.
Jonathan Giuffrida is a graduate student at the University of Chicago Harris School for Public Policy and is currently the product manager for Plenar.io. He can be reached at [email protected].



